Catalog Spark
Catalog Spark - A column in spark, as returned by. Pyspark.sql.catalog is a valuable tool for data engineers and data teams working with apache spark. We can create a new table using data frame using saveastable. R2 data catalog exposes a standard iceberg rest catalog interface, so you can connect the engines you already use, like pyiceberg, snowflake, and spark. Let us say spark is of type sparksession. Recovers all the partitions of the given table and updates the catalog. 本文深入探讨了 spark3 中 catalog 组件的设计,包括 catalog 的继承关系和初始化过程。 介绍了如何实现自定义 catalog 和扩展已有 catalog 功能,特别提到了 deltacatalog. Catalog is the interface for managing a metastore (aka metadata catalog) of relational entities (e.g. It acts as a bridge between your data and. Pyspark’s catalog api is your window into the metadata of spark sql, offering a programmatic way to manage and inspect tables, databases, functions, and more within your spark application. A column in spark, as returned by. It will use the default data source configured by spark.sql.sources.default. Spark通过catalogmanager管理多个catalog,通过 spark.sql.catalog.$ {name} 可以注册多个catalog,spark的默认实现则是spark.sql.catalog.spark_catalog。 1.sparksession在. Creates a table from the given path and returns the corresponding dataframe. Let us get an overview of spark catalog to manage spark metastore tables as well as temporary views. It exposes a standard iceberg rest catalog interface, so you can connect the. Caches the specified table with the given storage level. The catalog in spark is a central metadata repository that stores information about tables, databases, and functions in your spark application. Database(s), tables, functions, table columns and temporary views). We can create a new table using data frame using saveastable. It will use the default data source configured by spark.sql.sources.default. Creates a table from the given path and returns the corresponding dataframe. To access this, use sparksession.catalog. It provides insights into the organization of data within a spark. Catalog is the interface for managing a metastore (aka metadata catalog) of relational entities (e.g. These pipelines typically involve a series of. Let us say spark is of type sparksession. The pyspark.sql.catalog.gettable method is a part of the spark catalog api, which allows you to retrieve metadata and information about tables in spark sql. Creates a table from the given path and returns the corresponding dataframe. The pyspark.sql.catalog.listcatalogs method is a valuable tool for data. Let us get an overview of spark catalog to manage spark metastore tables as well as temporary views. There is an attribute as part of spark called. Pyspark.sql.catalog is a valuable tool for data engineers and data teams working with apache spark. It simplifies the management of metadata, making it easier to interact with and. The pyspark.sql.catalog.listcatalogs method is a. Creates a table from the given path and returns the corresponding dataframe. Caches the specified table with the given storage level. It exposes a standard iceberg rest catalog interface, so you can connect the. It provides insights into the organization of data within a spark. The catalog in spark is a central metadata repository that stores information about tables, databases,. A spark catalog is a component in apache spark that manages metadata for tables and databases within a spark session. Is either a qualified or unqualified name that designates a. The pyspark.sql.catalog.gettable method is a part of the spark catalog api, which allows you to retrieve metadata and information about tables in spark sql. Why the spark connector matters imagine. Let us get an overview of spark catalog to manage spark metastore tables as well as temporary views. Creates a table from the given path and returns the corresponding dataframe. We can also create an empty table by using spark.catalog.createtable or spark.catalog.createexternaltable. Why the spark connector matters imagine you’re a data professional, comfortable with apache spark, but need to tap. It acts as a bridge between your data and. A spark catalog is a component in apache spark that manages metadata for tables and databases within a spark session. Spark通过catalogmanager管理多个catalog,通过 spark.sql.catalog.$ {name} 可以注册多个catalog,spark的默认实现则是spark.sql.catalog.spark_catalog。 1.sparksession在. Let us say spark is of type sparksession. Let us get an overview of spark catalog to manage spark metastore tables as well as temporary views. Database(s), tables, functions, table columns and temporary views). A spark catalog is a component in apache spark that manages metadata for tables and databases within a spark session. Pyspark’s catalog api is your window into the metadata of spark sql, offering a programmatic way to manage and inspect tables, databases, functions, and more within your spark application. Catalog is the. Let us get an overview of spark catalog to manage spark metastore tables as well as temporary views. There is an attribute as part of spark called. The catalog in spark is a central metadata repository that stores information about tables, databases, and functions in your spark application. To access this, use sparksession.catalog. Catalog.refreshbypath (path) invalidates and refreshes all the. Pyspark.sql.catalog is a valuable tool for data engineers and data teams working with apache spark. Let us get an overview of spark catalog to manage spark metastore tables as well as temporary views. These pipelines typically involve a series of. Pyspark’s catalog api is your window into the metadata of spark sql, offering a programmatic way to manage and inspect. Caches the specified table with the given storage level. Creates a table from the given path and returns the corresponding dataframe. Pyspark’s catalog api is your window into the metadata of spark sql, offering a programmatic way to manage and inspect tables, databases, functions, and more within your spark application. R2 data catalog exposes a standard iceberg rest catalog interface, so you can connect the engines you already use, like pyiceberg, snowflake, and spark. To access this, use sparksession.catalog. A column in spark, as returned by. It exposes a standard iceberg rest catalog interface, so you can connect the. It simplifies the management of metadata, making it easier to interact with and. It will use the default data source configured by spark.sql.sources.default. Why the spark connector matters imagine you’re a data professional, comfortable with apache spark, but need to tap into data stored in microsoft. It allows for the creation, deletion, and querying of tables,. The catalog in spark is a central metadata repository that stores information about tables, databases, and functions in your spark application. The pyspark.sql.catalog.listcatalogs method is a valuable tool for data engineers and data teams working with apache spark. Database(s), tables, functions, table columns and temporary views). The pyspark.sql.catalog.gettable method is a part of the spark catalog api, which allows you to retrieve metadata and information about tables in spark sql. A catalog in spark, as returned by the listcatalogs method defined in catalog.
26 Spark SQL, Hints, Spark Catalog and Metastore Hints in Spark SQL Query SQL functions
Spark JDBC, Spark Catalog y Delta Lake. IABD
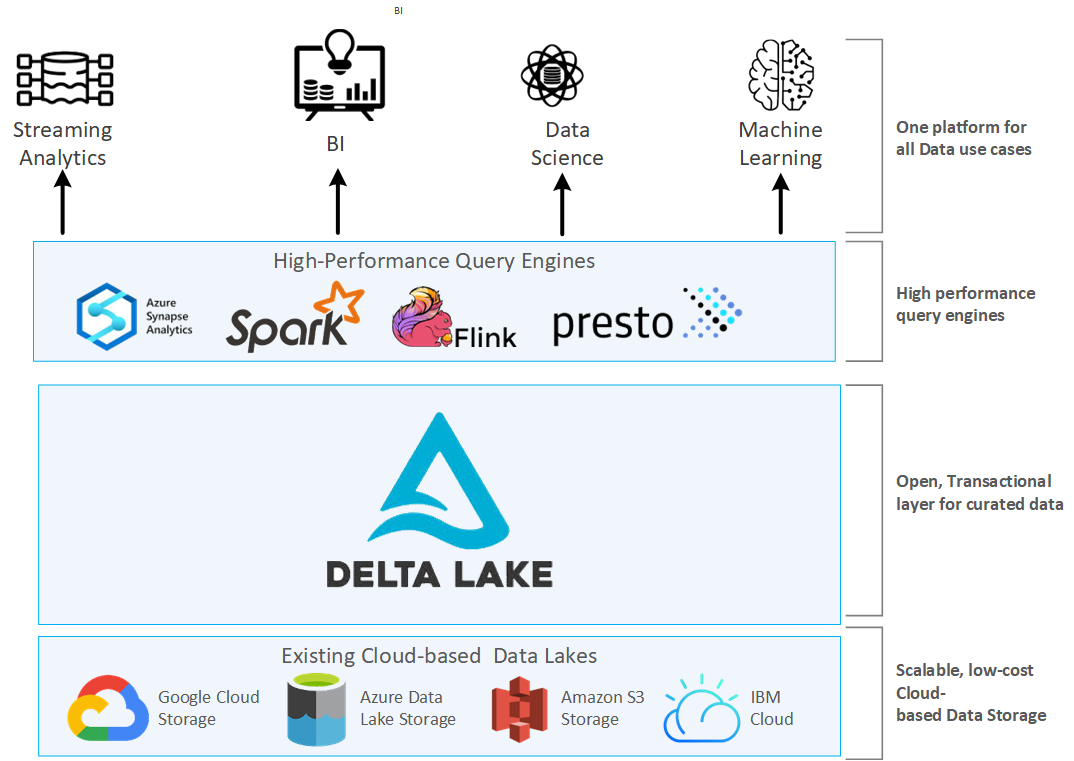
Spark Catalogs Overview IOMETE
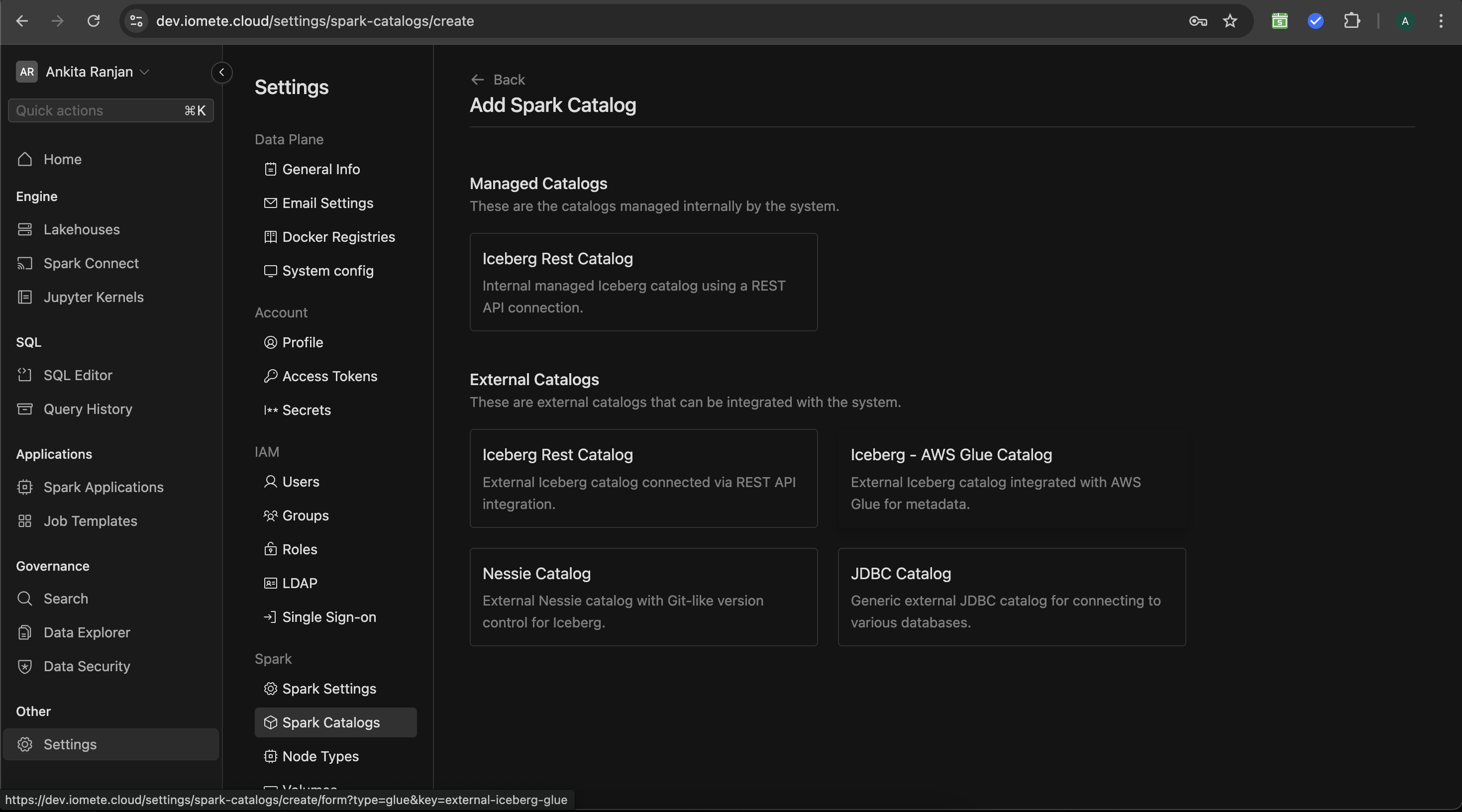
Spark Catalogs IOMETE

SPARK PLUG CATALOG DOWNLOAD
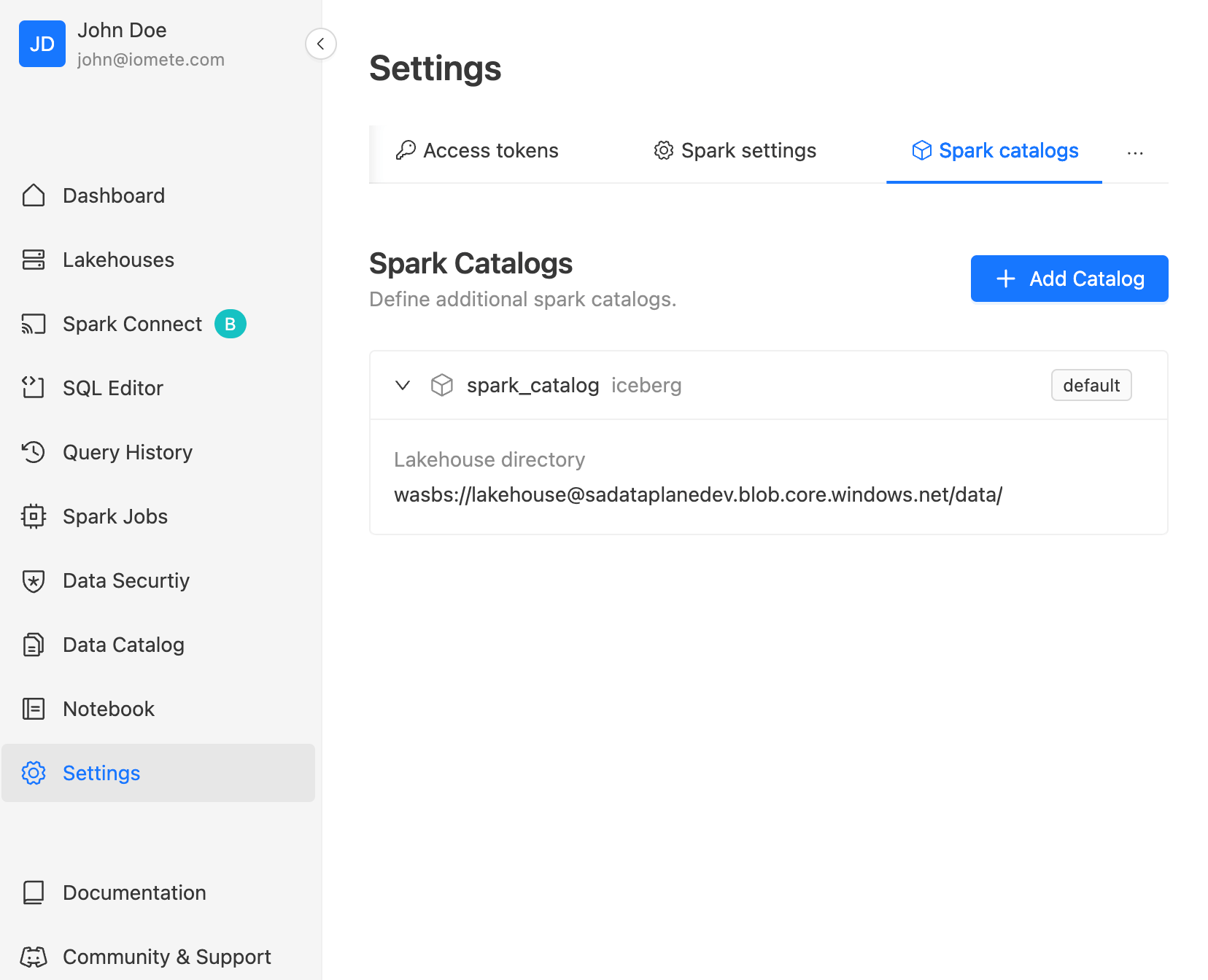
Spark Catalogs IOMETE

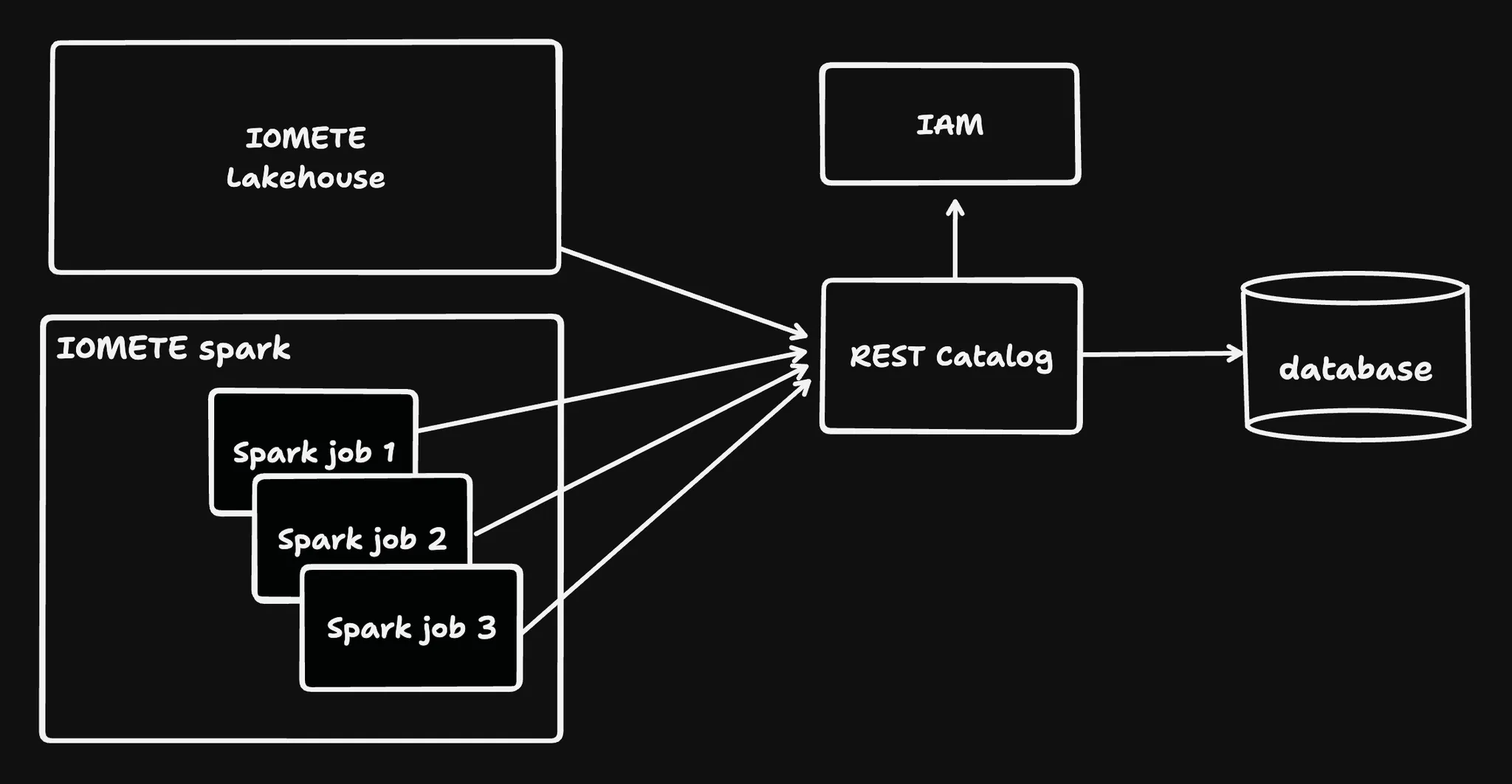
Configuring Apache Iceberg Catalog with Apache Spark

Spark Plug Part Finder Product Catalogue Niterra SA

DENSO SPARK PLUG CATALOG DOWNLOAD SPARK PLUG Automotive Service Parts and Accessories
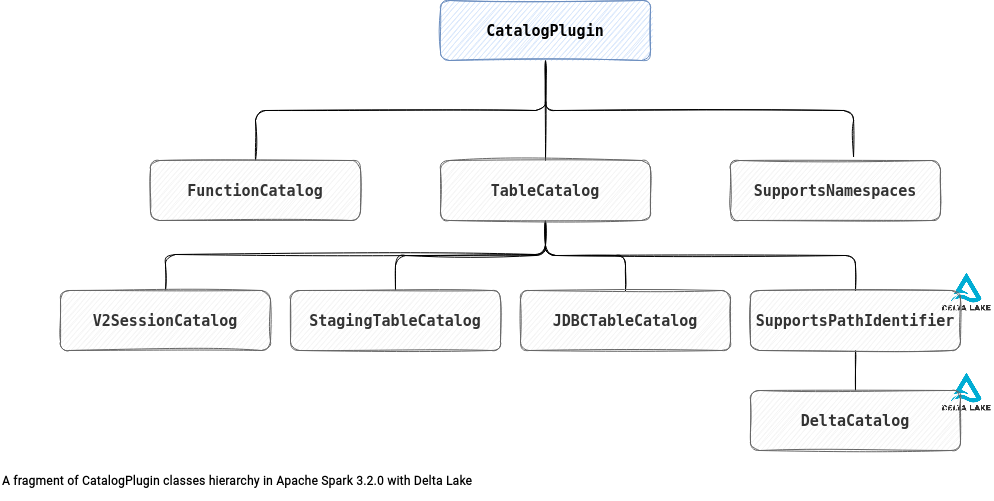
Pluggable Catalog API on articles about Apache Spark SQL
Let Us Get An Overview Of Spark Catalog To Manage Spark Metastore Tables As Well As Temporary Views.
It Provides Insights Into The Organization Of Data Within A Spark.
Catalog Is The Interface For Managing A Metastore (Aka Metadata Catalog) Of Relational Entities (E.g.
Is Either A Qualified Or Unqualified Name That Designates A.
Related Post: